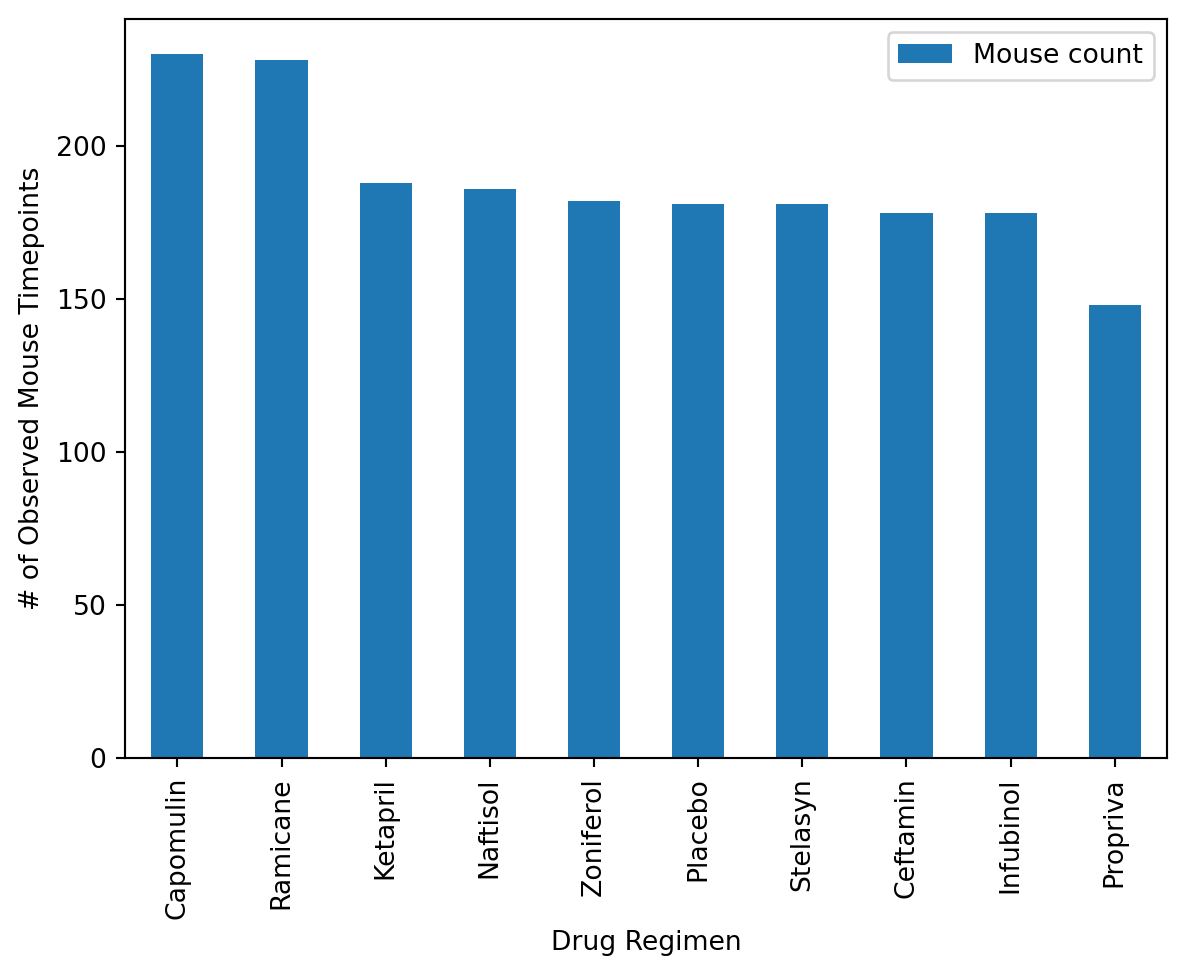
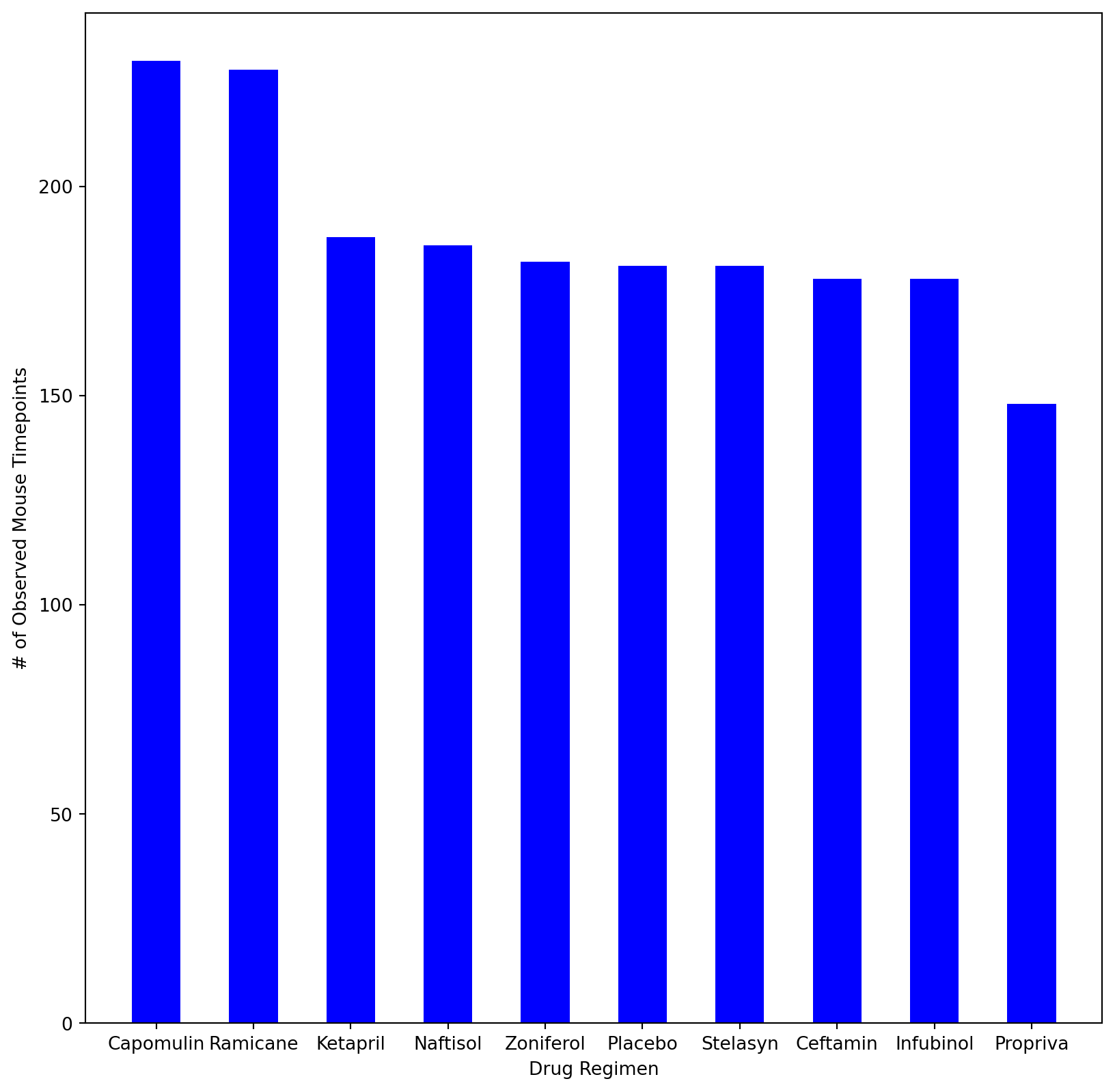
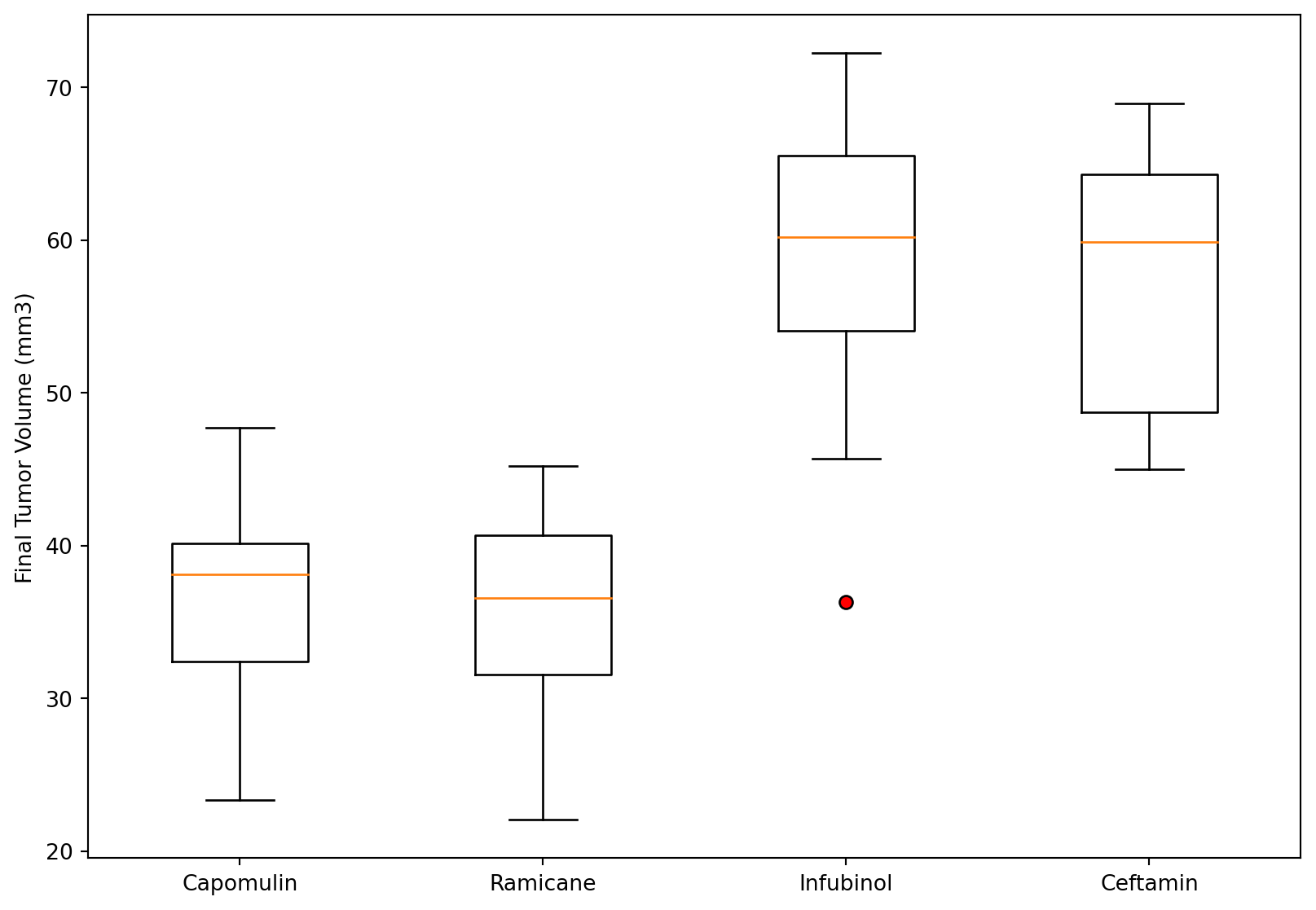
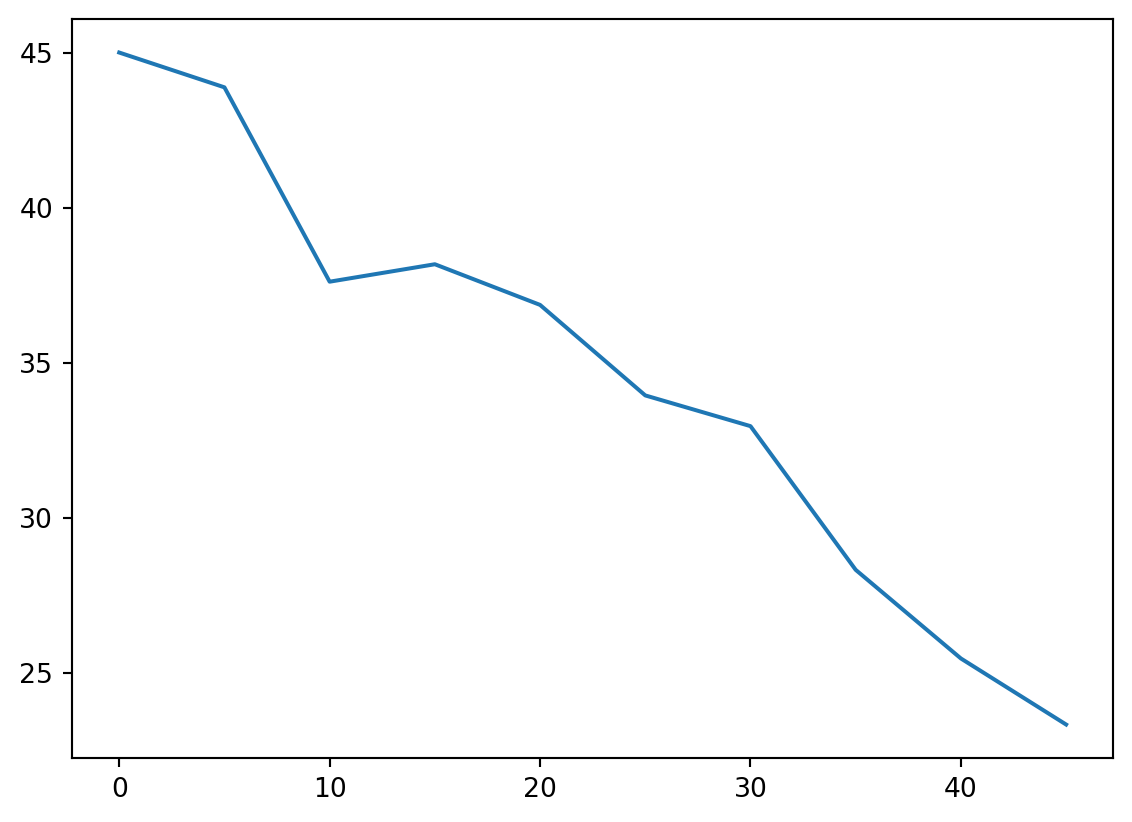
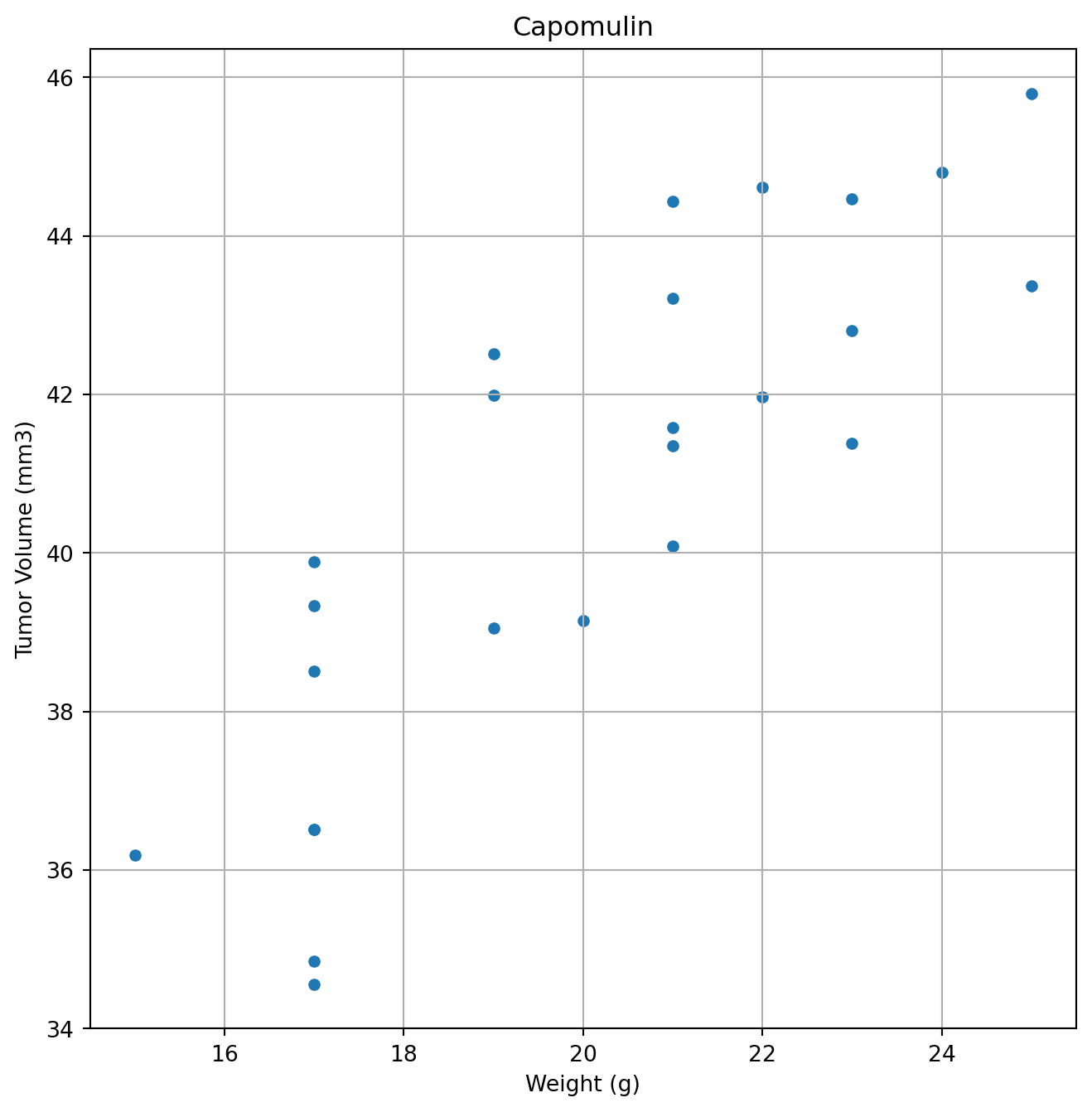
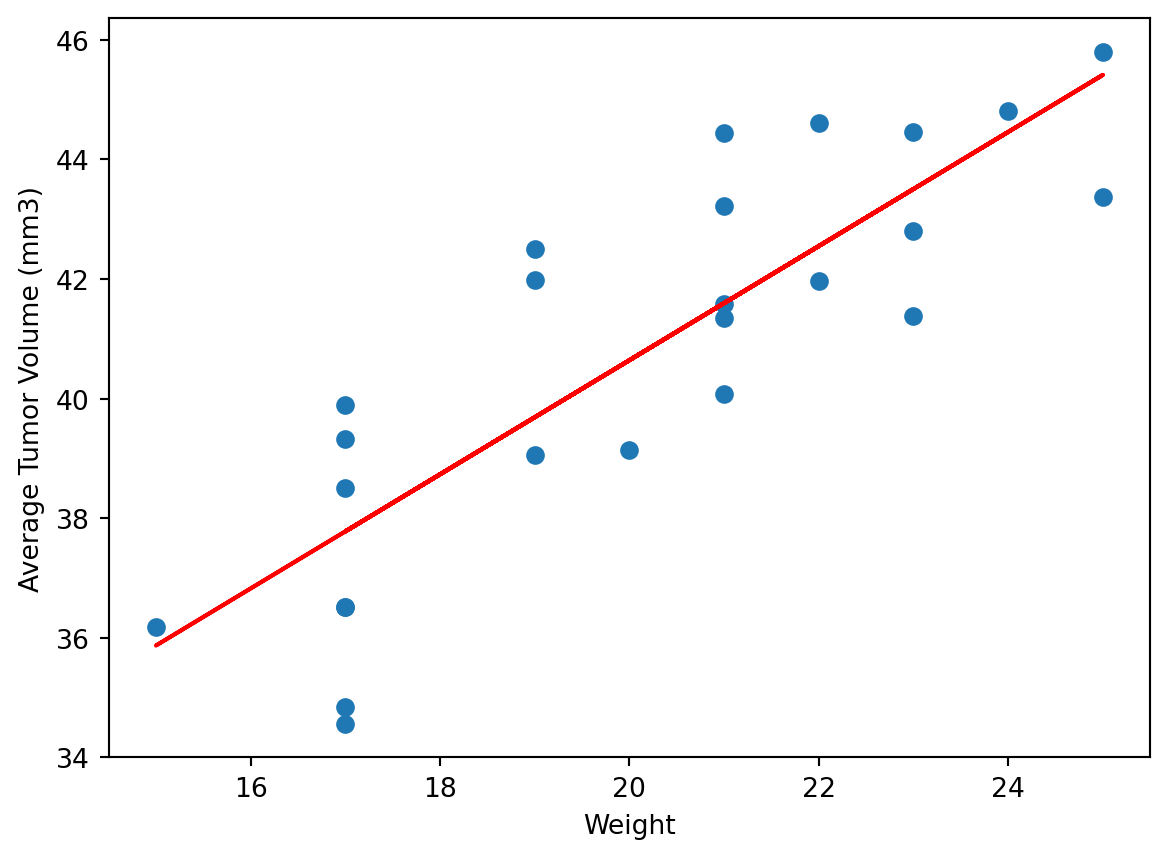
# Dependencies and Setupimport matplotlib.pyplot as pltimport pandas as pdimport scipy.stats as stimport numpy as npimport statisticsfrom statistics import variancefrom statistics import stdevfrom scipy.stats import sem# Study data filesmouse_metadata_path ="Mouse_metadata.csv"study_results_path ="Study_results.csv"# Read the mouse data and the study resultsmouse_metadata = pd.read_csv(mouse_metadata_path)study_results = pd.read_csv(study_results_path)# Combine the data into a single DataFramedataset1 = pd.merge(mouse_metadata,study_results, on="Mouse ID")dataset1 = dataset1[['Mouse ID', 'Timepoint', 'Tumor Volume (mm3)', 'Metastatic Sites', 'Drug Regimen', 'Sex', 'Age_months', 'Weight (g)']]# Display the data table for previewdataset1.to_csv('mousedata.csv', index=False, header=True)# Checking the number of mice.Num_of_Mice = dataset1['Mouse ID'].unique()#Num_of_Mice = dataset1['Mouse ID'].value_counts()Num_of_Mice2 =sum(pd.value_counts(Num_of_Mice))Num_of_Mice2# Create a clean DataFrame by dropping the duplicate mouse by its ID.dataset2 = dataset1.drop(dataset1[dataset1['Mouse ID'] =='g989'].index)dataset2# Generate a summary statistics table of mean, median, variance, standard deviation, and SEM of the tumor volume for each regimen# Use groupby and summary statistical methods to calculate the following properties of each drug regimen: # mean, median, variance, standard deviation, and SEM of the tumor volume. # Assemble the resulting series into a single summary DataFrame.dataset3 = dataset2.sort_values(by='Drug Regimen',ascending=True)dataset3#Groupby then summary stats / Calculating Mean categorized by drug typeMean_TV = dataset3.groupby(['Drug Regimen']).mean(['Tumor Volume (mm3)'])Mean_TV = Mean_TV.rename(columns={'Tumor Volume (mm3)':'Mean Tumor Volume'})Mean_TV = Mean_TV.drop(columns={'Timepoint','Metastatic Sites', 'Age_months', 'Weight (g)'})Mean_TV#Median Tumor VolumeMedian_TV = dataset3.groupby(['Drug Regimen']).median(['Tumor Volume (mm3)'])Median_TV = Median_TV.rename(columns={'Tumor Volume (mm3)':'Median Tumor Volume'})Median_TV = Median_TV.drop(columns={'Timepoint','Metastatic Sites', 'Age_months', 'Weight (g)'})Median_TV#Tumor Volume VarianceVariance_TV = dataset3.groupby(['Drug Regimen'])#Variance_TV = float(Variance_TV['Tumor Volume (mm3)']) #Variance_TV.var(['Tumor Volume (mm3)'])Variance_TVdataset4 = dataset3['Drug Regimen'].unique().tolist()dataset4#Getting the variance for each type of drug regimen#if drug regimen = x, then take Tumor Volume and add to specific drug regimen listDrug_Regimen = dataset3['Drug Regimen'].unique().tolist()Drug_Regimen#Volume list for drugsCapomulin_volumes = []Ceftamin_volumes = []Infubinol_volumes = []Ketapril_volumes = []Naftisol_volumes = []Placebo_volumes = []Propriva_volumes = []Ramicane_volumes = []Stelasyn_volumes = []Zoniferol_volumes = []for index, row in dataset3.iterrows(): current_drug = row['Drug Regimen']# Check if the current drug is 'Capomulin'if current_drug =='Capomulin':# If 'Capomulin', add the volume to the list Capomulin_volumes.append(row['Tumor Volume (mm3)'])if current_drug =='Ceftamin':# If 'Capomulin', add the volume to the list Ceftamin_volumes.append(row['Tumor Volume (mm3)'])if current_drug =='Infubinol':# If 'Capomulin', add the volume to the list Infubinol_volumes.append(row['Tumor Volume (mm3)'])if current_drug =='Ketapril':# If 'Capomulin', add the volume to the list Ketapril_volumes.append(row['Tumor Volume (mm3)'])if current_drug =='Naftisol':# If 'Capomulin', add the volume to the list Naftisol_volumes.append(row['Tumor Volume (mm3)'])if current_drug =='Placebo':# If 'Capomulin', add the volume to the list Placebo_volumes.append(row['Tumor Volume (mm3)'])if current_drug =='Propriva':# If 'Capomulin', add the volume to the list Propriva_volumes.append(row['Tumor Volume (mm3)'])if current_drug =='Ramicane':# If 'Capomulin', add the volume to the list Ramicane_volumes.append(row['Tumor Volume (mm3)'])if current_drug =='Stelasyn':# If 'Capomulin', add the volume to the list Stelasyn_volumes.append(row['Tumor Volume (mm3)'])if current_drug =='Zoniferol':# If 'Capomulin', add the volume to the list Zoniferol_volumes.append(row['Tumor Volume (mm3)'])# # Print the volumes of Capomulin# print("Capomulin Volumes:", Capomulin_volumes)Capomulin_volumes_v = variance(Capomulin_volumes)Ceftamin_volumes_v = variance(Ceftamin_volumes)Infubinol_volumes_v = variance(Infubinol_volumes)Ketapril_volumes_v = variance(Ketapril_volumes)Naftisol_volumes_v = variance(Naftisol_volumes)Placebo_volumes_v = variance(Placebo_volumes)Propriva_volumes_v = variance(Propriva_volumes)Ramicane_volumes_v = variance(Ramicane_volumes)Stelasyn_volumes_v = variance(Stelasyn_volumes)Zoniferol_volumes_v = variance(Zoniferol_volumes)Tumor_VV = [[Capomulin_volumes_v, Ceftamin_volumes_v, Infubinol_volumes_v, Ketapril_volumes_v, Naftisol_volumes_v, Placebo_volumes_v, Propriva_volumes_v, Ramicane_volumes_v, Stelasyn_volumes_v, Zoniferol_volumes_v], ['Capomulin', 'Ceftamin', 'Infubinol', 'Ketapril', 'Naftisol', 'Placebo','Propriva', 'Ramicane', 'Stelasyn', 'Zoniferol']]#Tumor_VVTumor_V_df = pd.DataFrame(Tumor_VV).transpose()Tumor_V_df.columns = ['Tumor Volume Variance', 'Drug Regimen']print((Tumor_V_df))#Standard Deviation of : print("Variance of Capomulin:", stdev(Capomulin_volumes))print("Variance of Ceftamin:", stdev(Ceftamin_volumes))print("Variance of Infubinol:", stdev(Infubinol_volumes))print("Variance of Ketapril:", stdev(Ketapril_volumes))print("Variance of Naftisol:", stdev(Naftisol_volumes))print("Variance of Placebo:", stdev(Placebo_volumes))print("Variance of Propriva:", stdev(Propriva_volumes))print("Variance of Ramicane:", stdev(Ramicane_volumes))print("Variance of Stelasyn:", stdev(Stelasyn_volumes))print("Variance of Zoniferol:", stdev(Zoniferol_volumes))Capomulin_volumes_sd = stdev(Capomulin_volumes)Ceftamin_volumes_sd = stdev(Ceftamin_volumes)Infubinol_volumes_sd = stdev(Infubinol_volumes)Ketapril_volumes_sd = stdev(Ketapril_volumes)Naftisol_volumes_sd = stdev(Naftisol_volumes)Placebo_volumes_sd = stdev(Placebo_volumes)Propriva_volumes_sd = stdev(Propriva_volumes)Ramicane_volumes_sd = stdev(Ramicane_volumes)Stelasyn_volumes_sd = stdev(Stelasyn_volumes)Zoniferol_volumes_sd = stdev(Zoniferol_volumes)Tumor_sd = [[Capomulin_volumes_sd, Ceftamin_volumes_sd, Infubinol_volumes_sd, Ketapril_volumes_sd, Naftisol_volumes_sd, Placebo_volumes_sd, Propriva_volumes_sd, Ramicane_volumes_sd, Stelasyn_volumes_sd, Zoniferol_volumes_sd], ['Capomulin', 'Ceftamin', 'Infubinol', 'Ketapril', 'Naftisol', 'Placebo','Propriva', 'Ramicane', 'Stelasyn', 'Zoniferol']]Tumor_sd_df = pd.DataFrame(Tumor_sd).transpose()Tumor_sd_df.columns = ['Tumor Volume Std. Dev.', 'Drug Regimen']print((Tumor_sd_df))#Standard error of the meanprint("Variance of Capomulin:", sem(Capomulin_volumes))print("Variance of Ceftamin:", sem(Ceftamin_volumes))print("Variance of Infubinol:", sem(Infubinol_volumes))print("Variance of Ketapril:", sem(Ketapril_volumes))print("Variance of Naftisol:", sem(Naftisol_volumes))print("Variance of Placebo:", sem(Placebo_volumes))print("Variance of Propriva:", sem(Propriva_volumes))print("Variance of Ramicane:", sem(Ramicane_volumes))print("Variance of Stelasyn:", sem(Stelasyn_volumes))print("Variance of Zoniferol:", sem(Zoniferol_volumes))Capomulin_volumes_sem = sem(Capomulin_volumes)Ceftamin_volumes_sem = sem(Ceftamin_volumes)Infubinol_volumes_sem = sem(Infubinol_volumes)Ketapril_volumes_sem = sem(Ketapril_volumes)Naftisol_volumes_sem = sem(Naftisol_volumes)Placebo_volumes_sem = sem(Placebo_volumes)Propriva_volumes_sem = sem(Propriva_volumes)Ramicane_volumes_sem = sem(Ramicane_volumes)Stelasyn_volumes_sem = sem(Stelasyn_volumes)Zoniferol_volumes_sem = sem(Zoniferol_volumes)Tumor_sem = [[Capomulin_volumes_sem, Ceftamin_volumes_sem, Infubinol_volumes_sem, Ketapril_volumes_sem, Naftisol_volumes_sem, Placebo_volumes_sem, Propriva_volumes_sem, Ramicane_volumes_sem, Stelasyn_volumes_sem, Zoniferol_volumes_sem], ['Capomulin', 'Ceftamin', 'Infubinol', 'Ketapril', 'Naftisol', 'Placebo','Propriva', 'Ramicane', 'Stelasyn', 'Zoniferol']]Tumor_sem_df = pd.DataFrame(Tumor_sem).transpose()Tumor_sem_df.columns = ['Tumor Volume Std. Err.', 'Drug Regimen']print((Tumor_sem_df))#Merging the datamerged_df = pd.merge(Mean_TV,Median_TV, on="Drug Regimen")merged_df = pd.merge(merged_df,Tumor_V_df, on="Drug Regimen")merged_df = pd.merge(merged_df,Tumor_sd_df, on="Drug Regimen")merged_df = pd.merge(merged_df,Tumor_sem_df, on="Drug Regimen")merged_df = merged_df.set_index('Drug Regimen')merged_df# A more advanced method to generate a summary statistics table of mean, median, variance, standard deviation,# and SEM of the tumor volume for each regimen (only one method is required in the solution)dataset3a = dataset3# Using the aggregation method, produce the same summary statistics in a single linedataset3a = dataset3a.groupby('Drug Regimen')['Tumor Volume (mm3)'].aggregate(["mean","median","var","std","sem"])dataset3a# Generate a bar plot showing the total number of rows (Mouse ID/Timepoints) for each drug regimen using Pandas.bp = dataset3['Drug Regimen'].value_counts().reset_index()bp.columns = ['Drug Regimen', 'Mouse count']# sorted(bp)plot1 = bp.plot.bar(x='Drug Regimen', y='Mouse count', rot=90)plot1.set_ylabel("# of Observed Mouse Timepoints")plot1.plot(figsize =(8,8))plot1# Generate a bar plot showing the total number of rows (Mouse ID/Timepoints) for each drug regimen using pyplot.fig = plt.figure(figsize = (10,10))plt.bar(bp['Drug Regimen'], bp['Mouse count'], color ='b', width =0.5)plt.xlabel("Drug Regimen")plt.ylabel("# of Observed Mouse Timepoints")plt.show()# Calculate the final tumor volume of each mouse across four of the treatment regimens: # Capomulin, Ramicane, Infubinol, and Ceftamin# Start by getting the last (greatest) timepoint for each mouseFinal_tp_mouse2 = dataset2.groupby('Mouse ID')['Timepoint'].max()Final_tp_mouse2 = Final_tp_mouse2.to_frame(name="Timepoint")# Merge this group df with the original DataFrame to get the tumor volume at the last timepointFinal_tp_mouse3 = pd.merge(Final_tp_mouse2, dataset2, how='left', left_on=['Mouse ID','Timepoint'],right_on=['Mouse ID','Timepoint'])Final_tp_mouse3#Put treatments into a list for for loop (and later for plot labels)# Capomulin, Ramicane, Infubinol, and Ceftamintreatments_list = ['Capomulin', 'Ramicane', 'Infubinol', 'Ceftamin']#Create empty list to fill with tumor vol data (for plotting)tumor_volume_list = []# # Create empty list to store IQR values for each treatmentiqr_values = []#Store outliersoutliers1 = []# # For loop list of treatmentsfor treatment in treatments_list: final_treatment = Final_tp_mouse3.loc[Final_tp_mouse3['Drug Regimen'] == treatment] tumor_volume_list.append(final_treatment['Tumor Volume (mm3)']) tumor_volume_check = final_treatment['Tumor Volume (mm3)']#Calculate the IQR for the current treatment quartiles = tumor_volume_check.quantile([.25,.5,.75]) lowerq = quartiles[0.25] upperq = quartiles[0.75] iqr = upperq-lowerq# Determine outliers using upper and lower bounds lower_bound = lowerq - (1.5*iqr) upper_bound = upperq + (1.5*iqr)# Identify potential outliers outliers = tumor_volume_check[(tumor_volume_check < lower_bound) | (tumor_volume_check > upper_bound)] outliers1.append(f"{treatment}'s potential outliers: {outliers} ")print(*outliers1, sep ="\n")# Generate a box plot that shows the distrubution of the tumor volume for each treatment group.fig, ax = plt.subplots(figsize =(10, 7))# Creating plotbp = ax.boxplot(tumor_volume_list, labels=treatments_list, flierprops =dict(marker ="o", markerfacecolor ="red"))# Add a title and labels to the plotax.set_ylabel('Final Tumor Volume (mm3)')# Display the plotplt.show()Capo_mouse1 = dataset1.loc[dataset1['Mouse ID'] =="s185"]Capo_mouse1# Generate a line plot of tumor volume vs. time point for a single mouse treated with Capomulincapomulin_line = plt.plot(Capo_mouse1['Timepoint'], Capo_mouse1['Tumor Volume (mm3)'])plt.show()average_observed_TV_Capo = dataset1.loc[dataset1['Drug Regimen']=="Capomulin"]average_observed_TV_Capo = average_observed_TV_Capo.groupby('Mouse ID').mean('Tumor Volume (mm3)')average_observed_TV_Capo# Generate a scatter plot of mouse weight vs. the average observed tumor volume for the entire Capomulin regimenaverage_observed_TV_Capo.plot(kind="scatter", x="Weight (g)", y="Tumor Volume (mm3)", grid=True, figsize=(8,8), title="Capomulin")plt.show()from scipy.stats import linregress# Calculate the correlation coefficient and a linear regression model # for mouse weight and average observed tumor volume for the entire Capomulin regimenx_values = average_observed_TV_Capo['Weight (g)']y_values = average_observed_TV_Capo["Tumor Volume (mm3)"]#calculating correlation coefficientcorrelation = st.pearsonr(x_values,y_values)print(f"The correlation between mouse weight and the average tumor volume is {round(correlation[0],2)}")#printing correlation line(slope, intercept, rvalue, pvalue, stderr) = linregress(x_values, y_values)regress_values = x_values * slope + interceptline_eq ="y = "+str(round(slope,2)) +"x + "+str(round(intercept,2))plt.scatter(x_values,y_values)plt.plot(x_values,regress_values,"r-")plt.annotate(line_eq,(5.8,0.8),fontsize=15,color="red")plt.xlabel('Weight')plt.ylabel('Average Tumor Volume (mm3)')plt.show()
Tumor Volume Variance Drug Regimen
0 24.947764 Capomulin
1 39.290177 Ceftamin
2 43.128684 Infubinol
3 68.553577 Ketapril
4 66.173479 Naftisol
5 61.168083 Placebo
6 43.852013 Propriva
7 23.486704 Ramicane
8 59.450562 Stelasyn
9 48.533355 Zoniferol
Variance of Capomulin: 4.9947736805840215
Variance of Ceftamin: 6.2681877184141985
Variance of Infubinol: 6.5672432670669405
Variance of Ketapril: 8.279708757706759
Variance of Naftisol: 8.134708291473338
Variance of Placebo: 7.821002681031188
Variance of Propriva: 6.622085246583617
Variance of Ramicane: 4.846308280753017
Variance of Stelasyn: 7.7104190335782645
Variance of Zoniferol: 6.966588504381904
Tumor Volume Std. Dev. Drug Regimen
0 4.994774 Capomulin
1 6.268188 Ceftamin
2 6.567243 Infubinol
3 8.279709 Ketapril
4 8.134708 Naftisol
5 7.821003 Placebo
6 6.622085 Propriva
7 4.846308 Ramicane
8 7.710419 Stelasyn
9 6.966589 Zoniferol
Variance of Capomulin: 0.32934562340083096
Variance of Ceftamin: 0.46982053275261093
Variance of Infubinol: 0.49223569380113824
Variance of Ketapril: 0.6038598237739697
Variance of Naftisol: 0.5964657512424235
Variance of Placebo: 0.5813305510593877
Variance of Propriva: 0.544332054194047
Variance of Ramicane: 0.3209546065084817
Variance of Stelasyn: 0.5731109332771458
Variance of Zoniferol: 0.5163978968332169
Tumor Volume Std. Err. Drug Regimen
0 0.329346 Capomulin
1 0.469821 Ceftamin
2 0.492236 Infubinol
3 0.60386 Ketapril
4 0.596466 Naftisol
5 0.581331 Placebo
6 0.544332 Propriva
7 0.320955 Ramicane
8 0.573111 Stelasyn
9 0.516398 Zoniferol